Zynq-7000 AP SoC Performance – Gigabit Ethernet achieving the best performance
Table of Contents
Document History
| Date | Version | Author | Description of Revisions |
|---|---|---|---|
| 06/15/2015 | 0.1 | Upender Cherukupally | Release 1.0 |
Overview
This techtip describes the challenges in achieving the best Ethernet performance and best design practices to achieve the better performance using the Zynq-7000 AP SoC. This techtip explains briefly on the various solutions available for the achieving the better performance using the Zynq-7000 AP SoC, steps to re-create, compile and run the design where ever it is possible. This paper also explains various ways to implement the TCP/IP protocols and discusses the advantages on each implementations like TCP/IP offload engine, software implementations of stack like lwIP and Linux Ethernet sub-system.
Zynq-7000 AP SoC has an in-built dual Giga bit Ethernet controllers which can support 10/100/1000 Mb/s EMAC configurations compatible with the IEEE 802.3-2008 standard. The Programming Logic (PL) sub system of the Zynq-7000 AP SoC can also be configured with additional soft AXI EMAC controllers if the end application requires more than two Giga bit Ethernet Controller. Following is the example block diagram of the Zynq-7000 AP SoC with GEMACs using the ZC706 Development board
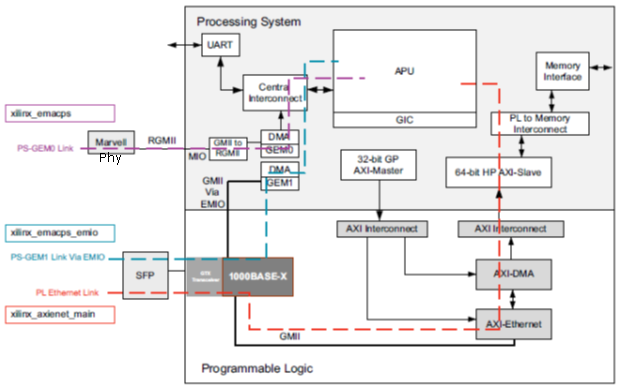 |
| Figure 1: Gigabit Ethernet Design block diagram using Zynq-7000 AP SoC |
Above example scenario shows all the possible gigabit Ethernet MAC configurations using the ZC706 board.
- PS-GEM0 is connected to the Marvell PHY through the reduced gigabit media independent interface (RGMII), which is the default setup for the ZC706 board.
- PS Ethernet (GEM1) that is connected to a 1000BASE-X physical interface in PL through an EMIO interface and
- PL Ethernet implemented as soft logic in PL and connected to the 1000BASE-X physical interface in PL.
The PS-GEM1 and the PL Ethernet share the same 1000 BASE-X PHY so only one will be available at a given point of time on this board among these two configurations. PS GEM0, PS GEM1 supports max frame size 1522 bytes. There can be frame size up to 16k which called jumbo frame. The AXI EMAC in PL can be configured to have the Jumbo frame support which actually reduces the number of transfer for a large data size which is of greater/multiples of the jumbo frame size. The Jumbo frame support in AXI EMAC is the major difference between PS and PL EMACs.
This techtip explains the following sections:
- Gigabit Ethernet solutions using the Zynq-7000 AP SoC and application data path,
- What is Ethernet performance,
- Types of TCP/IP stack implementations,
- Solutions readily available using the Zynq-7000 AP SoC,
- Techniques which can be applied and achieve the maximum possible Ethernet data performance
Implementation
| Implementation Details | |
| Design Type | PS only |
| SW Type | Zynq-7000 AP SoC Linux & Zynq-7000 AP SoC Baremetal |
| CPUs | 2 ARM Cortex-A9: SMP Linux and Baremetal configurations |
| PS Features |
|
| Boards/Tools | ZC702 Kit & ZC706 Kit |
| Xilinx Tools Version | Vivado & SDK 2015.1 or latest |
| Other Details | - |
| Files Provided | |
| ZC702_ZC706_ReadyToUseImages | Contain folders: Source, SD Card Images required to follow the procedure below |
Ethernet Performance
With the Ethernet frame of size 1538 bytes, there can be a maximum of 81275 frames per second on 1000 Mbps (or 1Gbps), half-duplex (one way) Ethernet pipe. In other words, this would mean, that the Ethernet network interface would be subjected to a frame transaction in every 12.3 us. So, in order to sustain the line rate of 1 Gbps, the software on the host CPU must finish its work of handling & processing of a frame with 12.3 us and then be available to handle the next arriving frame. Such a time bound execution will ensure that software is working in tandem with the Ethernet hardware. For any reason, if the software is not able to handle and process a frame or packet within the stipulated time (of 12.3 us), then, it will not be able to strike the much needed equilibrium with the Ethernet hardware to sustain the line rate of 1 Gbps. The lack of tandem between software and hardware will create either a backpressure (if doing RX) or a starvation (if doing TX) on the hardware. A sustained backpressure will eventually force the Ethernet hardware to overrun and tail-drop the frames from the Ethernet wire, whereas starvation will instantly cause the hardware to under-run and the wire would be underutilized.The following sections explains:
- Features of the Zynq-7000 AP SoC for implementing the Ethernet based solution to achieve the best performance
- End to end data flow of the Ethernet data and best design practices in hardware as well as software design flows
- List of all the available and ready to use reference designs for Ethernet based solutions using the Zynq-7000 AP SoC
Ethernet Data movement in Zynq-7000 AP SoC
The Gigabit Ethernet MAC Controller on Zynq Processing System comprises of three blocks.- MAC Controller
- FIFO(Packet Buffer)
- Ethernet DMA Controller
The Ethernet DMA controller is attached to the FIFO to provide a scatter-gather capability for packet data storage in a Zynq processing system. The Ethernet DMA uses separate transmit and receive lists of buffer descriptors, with each descriptor describing a buffer area in memory
Receive Path:
The data received by the controller is written to pre-allocated buffer descriptors in system memory. These buffer descriptor entries are listed in the receive buffer queue. The Receive-buffer Queue Pointer register of the Ethernet DMA points to this data structure on initialization and uses it to continuously and sequentially to copy the Ethernet packet received in the Ethernet FIFO to Memory address specified in the receive buffer queue
Rx Ring buffers and Tx Ring buffers location can be in DDR or OCM and access latencies of these memories, the speed at which the instructions executes for packet processing will also improves the overall performance
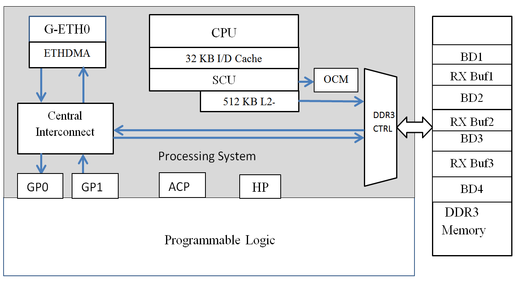 |
| Figure 2: Ethernet Data movement in Zynq-7000 AP SoC |
When an Ethernet Packet is received by the MAC, the Ethernet DMA uses the address in the RX Buffer descriptor to push the packet that has been buffered in the Packet Buffer on Ethernet interface to DDR3 memory, via the central interconnects.
Data Receive Path: ETH0 -> ETH0 DMA (32-bit) -> Central Interconnect -> DDR3 Memory Controller (64-bit AXI).
Transmit Path
In case of transmit the Ethernet DMA uses the address in the TX Buffer descriptor to pull data from DDR3 Memory, through the central interconnect and finally to the ETH0 Interface.
Data Transmit path: DDR3 Memory Controller (64-bit AXI) -> Central Interconnect -> ETH0 DMA (32-bit) -> ETH0
The Ethernet application software access the application data through the cache, so from the DDR memory to the cache access latency will also be added to the overall the access time from the source of the data to the destination at the application software. To improve further the application data buffers can be stored in OCM.
The inbuilt features like built in DMA engines, MAC address filtering and intermediate buffers in both transmit and receive path helps in achieving the better performance using the PS EMAC controllers. The PS EMAC controllers allow multiple packets to be buffered in both transmit and receive directions. This allows the DMA to withstand far greater access latencies on the AXI and make more efficient use of the AXI bandwidth to:
- Discard packets with error on the receive path before they are partially written out of the DMA thus saving AXI bus bandwidth and driver processing overhead
- Retry collided transmit frames from the buffer, thus saving AXI bus bandwidth,
- Implement transmit IP/TCP/UDP checksum generation offload
Ethernet Protocols Implementations
There are following three general approaches for implementing the using the TCP/IP protocol software:
- If a generic/ fully featured operating system like Linux is used, then the series of instructions and execution flow may take bit longer time as part of the packet handling, processing, context switching, user space / kernel space transactions, data copy (load store) and interrupt thrashing. And there would be definitely still more work that CPU would be required to do before it can come back to Ethernet hardware to pick up or provide the next frame such as user space to kernel space transitions and mode switches etc. This wiki page explains few techniques to improve the performance in the implementations line Linux stacks. This techtip also gives the pointers to the example reference designs and documentation which uses the Linux for TCP/IP solutions.
- On the other hand, the tailored, customized and relatively lightweight operating system like freeRTOS and lightweight (lwIP) TCP/IP implementations is used then the sequence of execution flow may showcase improvised numbers for handling & processing of the network frames or packets.
- A micro kernel or similar tight loop software, with no Internet Protocol stack & having the sole functionality of handling the network packets and incorporating a very minimal custom logic for packet processing might be able to sustain the good line rate.
Linux Networking SW TCP/IP stack implementation
The TCP/IP or UDP/IP protocol implementation also plays a major role in overall Ethernet performance. Following is the Linux SW stack implementation |
| Figure 3: Linux TCP/IP SW stack implementation |
Though the Linux kernel is based on monolithic architecture and works on sys call interface which involves the mode switches between user and kernel, it tries to optimize the system where ever it is possible to do so. Following are the few techniques used to achieve better performance
Memory allocation is a key factor in the performance of any TCP/IP stack. Most other TCP/IP implementations have a memory implementation mechanism that is independent from the OS. However, the Linux implementation took a different approach by using the slab cache method, which is used for other internal kernel allocation and this method has been adapted for socket buffers. With slab allocation, memory chunks suitable to fit data objects of certain type or size are pre-allocated.
The slab allocator keeps track of these chunks, known as caches, so that when a request to allocate memory for a data object of a certain type is received, it can instantly satisfy the request with an already allocated slot. Destruction of the object does not free up the memory, but only opens a slot which is put in the list of free slots by the slab allocator. The next call to allocate memory of the same size will return the now unused memory slot. This process eliminates the need to search for suitable memory space and greatly alleviates memory fragmentation.
Linux has the capability of deferring interrupt-level work to kernel threads to decrease latency problems. The goal of the OS should be to minimize context switches while a packet is processed by the stack. Linux uses softirqs to handle most of the internal processing
Minimal data copying
To achieve better performance the implementation should minimize the amount of copying to move a packet of data from the application, down through the stack to the transmission media. Linux provides scatter gather DMA support where the socket buffers are set up to allow for the direct transmission of lists of TCP segments. At the user level, when data is transferred through a socket, copying can be avoided and data can be mapped directly into the user space from the kernel space.Endianness
TCP/IP or UDP/IP packet format follows the big endian notation and if the CPU core is in little endian then the endian conversion should happen at the software layers in both TX and Rx paths to interpret the data.Design example on how to use PL AXI Ethernet implementations/ jumbo frames support in Zynq-7000 AP SoC
Jumbo frames are used in high data intensive applications. The packet size is 16384 bytes. The larger frame size improves the performance by reducing the number of the fragments for a given data size.The XAPP-1082 provides details on how to use the jumbo frames support available in AXI EMAC for improved performance.
Following is the block diagram of the design provided with XAPP1082 using the ZC706 development kit:
|
| Figure 4: Block diagram of the design implemented as part of XAPP1082 |
The PS GEM1 and PL AXI Ethernet shares the 1000Base-X PHY so only either PSGEM1 or PLAXI Ethernet can be used at given point of time.
The complete design details and design files can be obtained from XAPP1082
http://www.xilinx.com/support/documentation/application_notes/xapp1082-zynq-eth.pdf
Steps to create the PS EMIO Ethernet solution, PL Ethernet solution and setting up the Embedded Linux for Zynq, refer the following link:
http://www.wiki.xilinx.com/Zynq+PL+Ethernet
Following are some of the techniques which can be applied to get the better performance from user space
These commands can be applied once the Linux kernel/XAPP1082 image is booted on Zynq-7000 AP SoC- 1.Tuning the task priorities using the ‘nice’ system call form the user space
- Run the command ps –all to get the list of tasks and their PID, identify the network tasks and change the priorities using the nice sys call. The example format is shown below
- root@linux#nice –n -3 program; renice level PID
- 2.CPU affinity for the interrupt handlers/task: This will make sure the minimal cache operations as complete application/task is attached to a single core.
- root@linux#echo 01 > /proc/irq/19/smp_affinity
- 3.To share the load between the two Cortex A9s Taskset2 utility can be used while launching the Ethernet based applications
- 4.Window Size is also a configurable options for better performance. In a connection between a client and a server, the client tells the server the number of bytes it is willing to receive at one time from the server; this is the client's receive window, which becomes the server's send window. Likewise, the server tells the client how many bytes of data it is willing to take from the client at one time; this is the server's receive window and the client's send window. There are chances that window size will drop down to zero dynamically if the receiver is not able to process the data as fast as sender is sending the data. Larger the size then more chances to get the better performance. In Linux environment the Window size settings can be tuned by following the steps explained in the following links:
- http://www.cyberciti.biz/faq/linux-tcp-tuning/
- (linux-kernel/Documentation/networking/ip-sysctl.txt) http://www.cyberciti.biz/files/linux-kernel/Documentation/networking/ip-sysctl.txt
- While using the iperf bench marking the -w option can be used to specify the window size.
Bare metal lwIP TCP/IP stack
lwIP TCP/IP stack can be used in RAW API/standalone mode and Netconn API/Socket API using the RTOS features.- RAW Mode: This mode involves direct usage of EMAC driver calls, there is no middle level OS in communication with HW
- Socket Mode: This mode uses the RTOS feature like message queues, threads to achieve the parallelism in software for both RX and TX
Design example on how to implement a bare metal TCP/IP stacks with and without the RTOS
The light weight TCP/IP stack implementations like lwIP and uIP can also significantly improves the Ethernet performance. The lwIP port for Zynq-7000 AP SoC with RAW API and Socket API modes is available with the XAPP-1026. This appnote provides all the best possible configurations of the lwIP TCP/IP stack to achieve the better performance with various Ethernet based applications like TFTP, Webserver, telnet in bare metal implementation.The complete design details and design files can be obtained from XAPP1026 XAPP1026 (http://www.xilinx.com/support/documentation/application_notes/xapp1026.pdf)
As explained in the above appnote the lwIP TCP/IP stack is available for the designers as library as part of the SDK. To achieve the better performance designers can choose the following options of the lwIP library in SDK settings. lwIP TCP/IP performance settings for better performance:
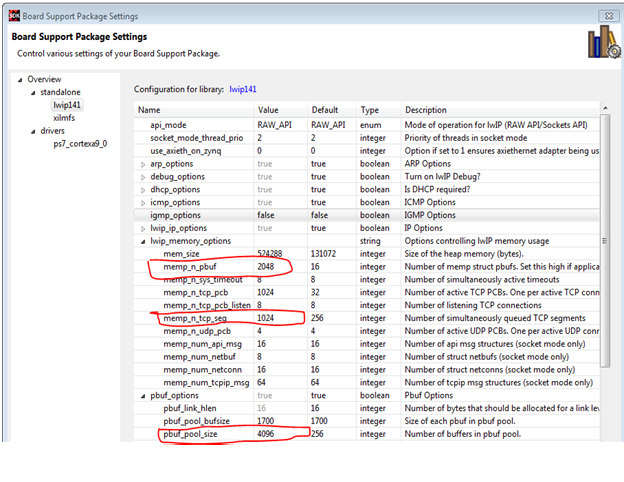 |
| Figure 5: lwIP TCP/IP performance settings |
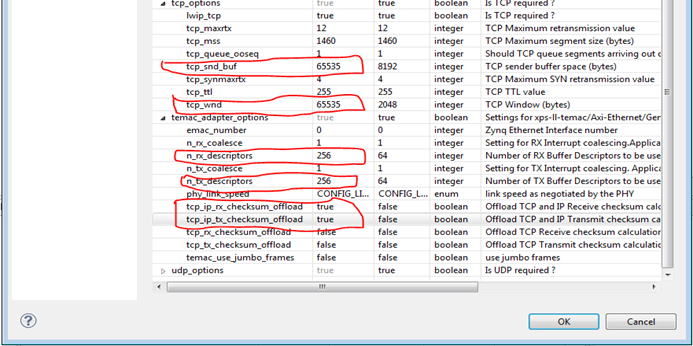 |
| Figure 6 : lwIP stack settings for socket mode/when used along with RTOS |
Conclusion
This techtip explained the Gigabit Ethernet solutions using the Zynq-7000 AP SoC, application data path, Ethernet performance, types of TCP/IP stack implementations, solutions readily available using the Zynq-7000 AP SoC, techniques which can be applied and achieve the maximum possible Ethernet data performance.
© Copyright 2019 - 2022 Xilinx Inc. Privacy Policy