This page describes a prototype system for a more complete Linux User Space DMA based on an earlier wiki page Linux DMA From User Space.
Table of Contents
| Table of Contents | ||
|---|---|---|
|
Introduction
This prototype is numbered as 2.0 to indicate that it is the next major version after the older prototype. The major concepts are the same as the previous design and the user is referred to Linux DMA From User Space for those details. The prototype system is based on Zynq UltraScale+ MPSOC on the ZCU102 board but could be moved to any board as there are no board level interfaces required. It is only specific to MPSoC with the use of system coherency such that it could be adapted to Zynq or Versal. The prototype was tested with the Xilinx 2020.1 tools (Vivado and PetaLinux).
System Requirements and Assumptions
The goal of the prototype is to emulate a real-life system without the need for device specific hardware such as an A to D converter. The following high level requirements are the basis for the prototype.
A DMA is used to move the data from the producer (input device) into system memory to minimize CPU utilization.
After the data is in system memory the CPU reads all the data from the input device to verify the integrity such that cached memory is required for reasonable performance.
A continuous stream of data from the input device at a constant rate is to be processed rather than only a snapshot of data from a window of time.
Hardware
AXI DMA
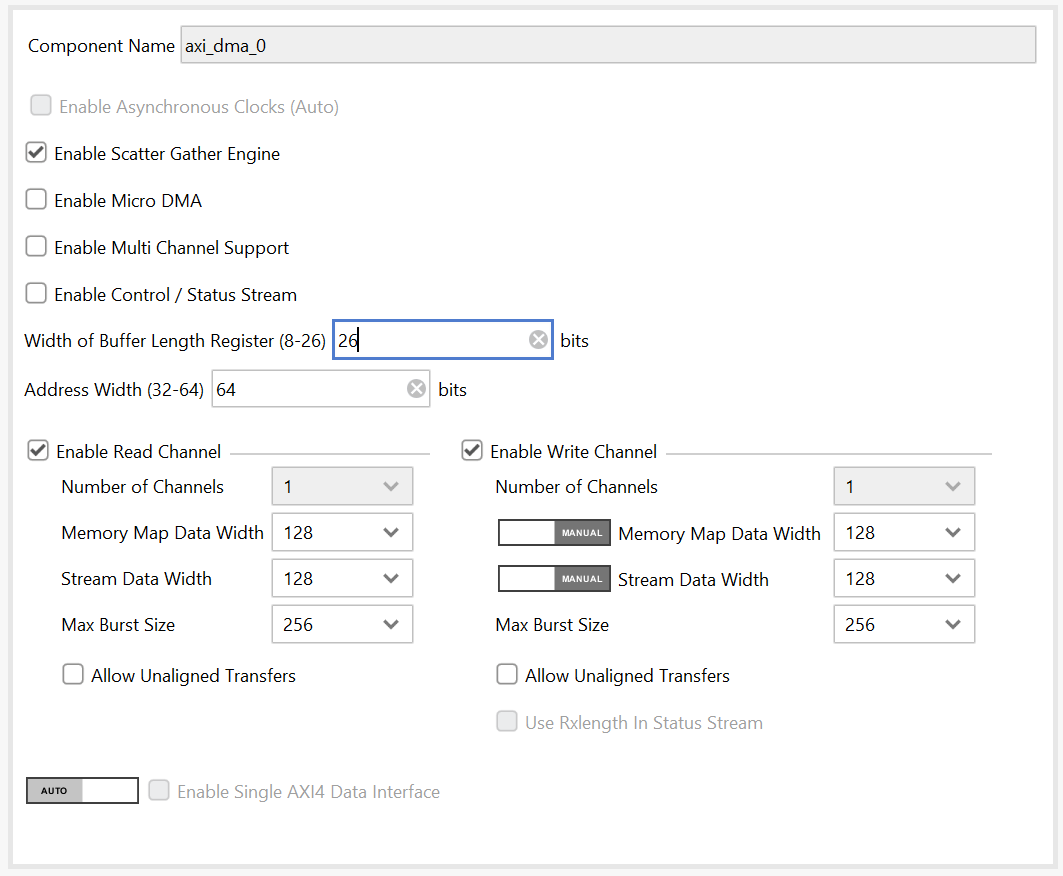
The primary part of the hardware platform is an AXI DMA IP connected to MPSOC. The AXI DMA is used as this would be typical in real systems using an receive channel with an AXI stream input. In the prototype the AXI DMA is configured with both channels, a memory to stream channel referred to as the transmit channel in the prototype, and a stream to memory channel referred to as a receive channel in the prototype. The transmit channel AXI stream is looped back to the receive channel AXI stream. Scatter gather is being used as it is better for offloading the CPU.
The following illustrations show the details of the prototype system in Vivado.
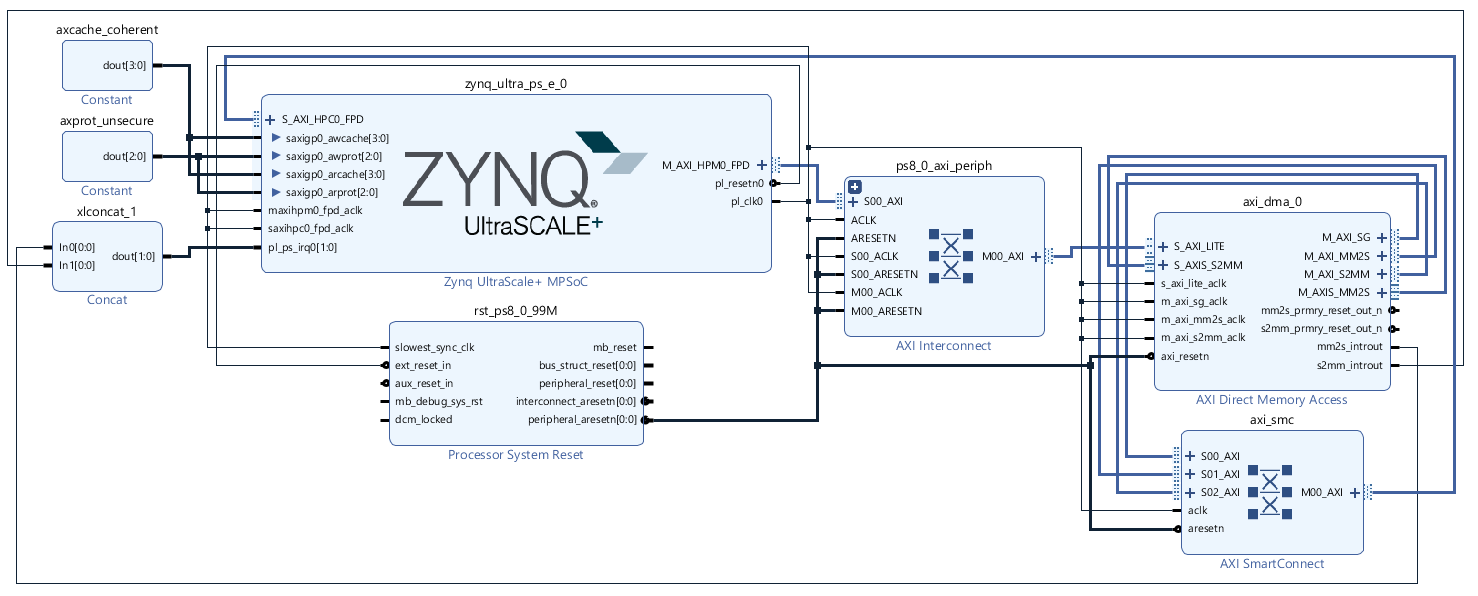
Receive Only
The following block diagram snippets illustrate the principles of building a receive only system in the simplest way. Read and Write channels in the DMA are both enabled to minimize the changes to the system which allows the kernel driver to still operate without any changes.
A data generator is created and connected to the S2MM side of the DMA. The data generator creates an incrementing 32 bit data input driving tdata, tlast and tvalid signals for the AXI stream. The data generator is controller by the tready signal from the DMA together with a general purpose output (GPO) controlled by the software. The GPO is used to enable the data generator after the software has initialized the DMA. The AXI DMA has some startup behavior that is not friendly for a data generator as it asserts tready for a few cycles after reset and before it has been initialized by software so that data is out of sync without the use of the GPO. The GPO disables the data generator on reset until the software enables it.
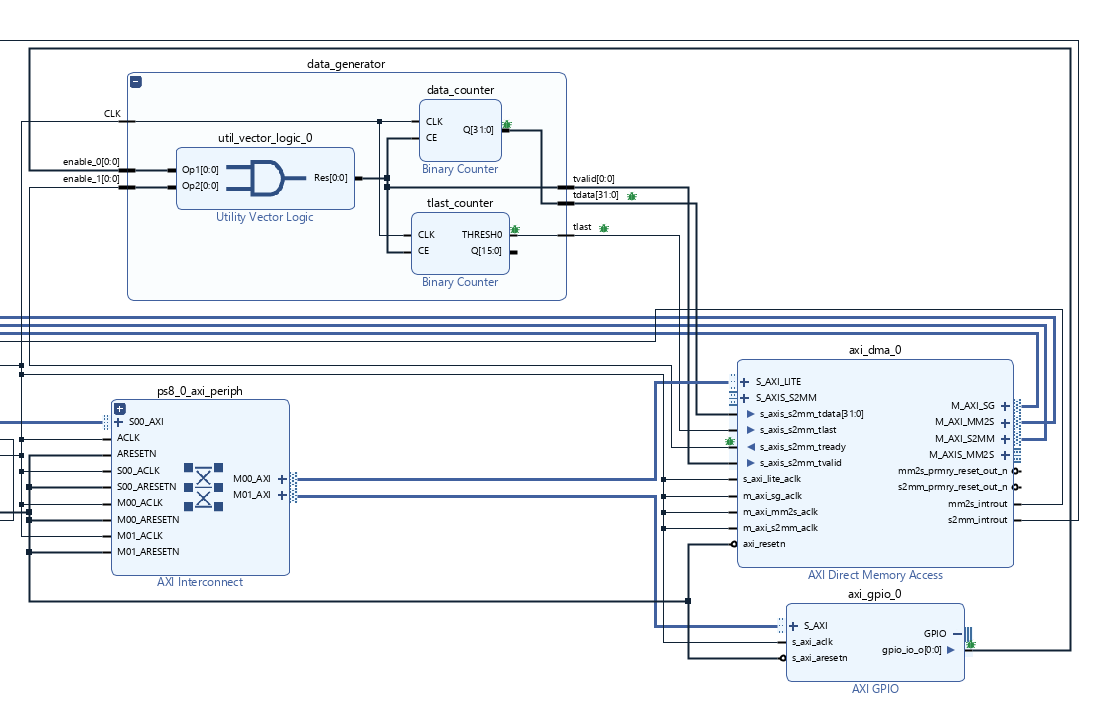
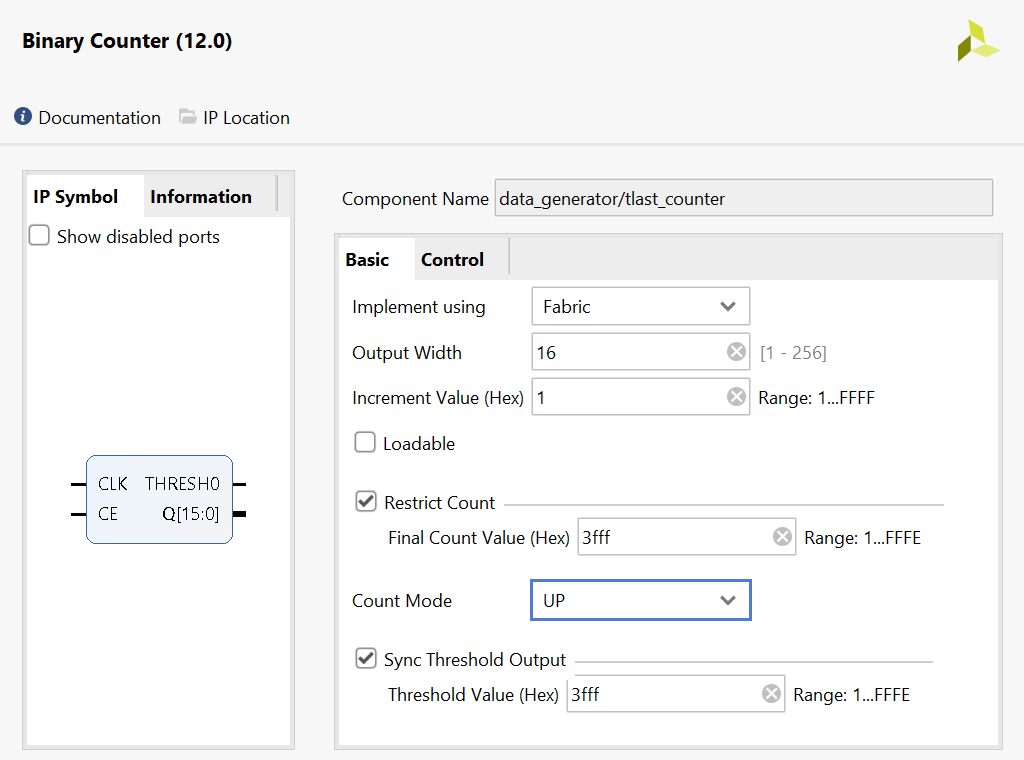
The data generator only supports a fixed size packet that is determined by the tlast counter which is a counter of 32 bit words rather than bytes. The tlast and tdata binary counters utilize the CE signal to prevent counting when the DMA is not ready for data. The tlast binary counter utilizes the threshold output to indicate when the last data is present and assert the tlast signal. The following binary counter configuration illustrates the tlast counter being configured for 64K byte packets (16K 32 bit words) with the tlast signal being created on the last 32 bit data.
Coherency
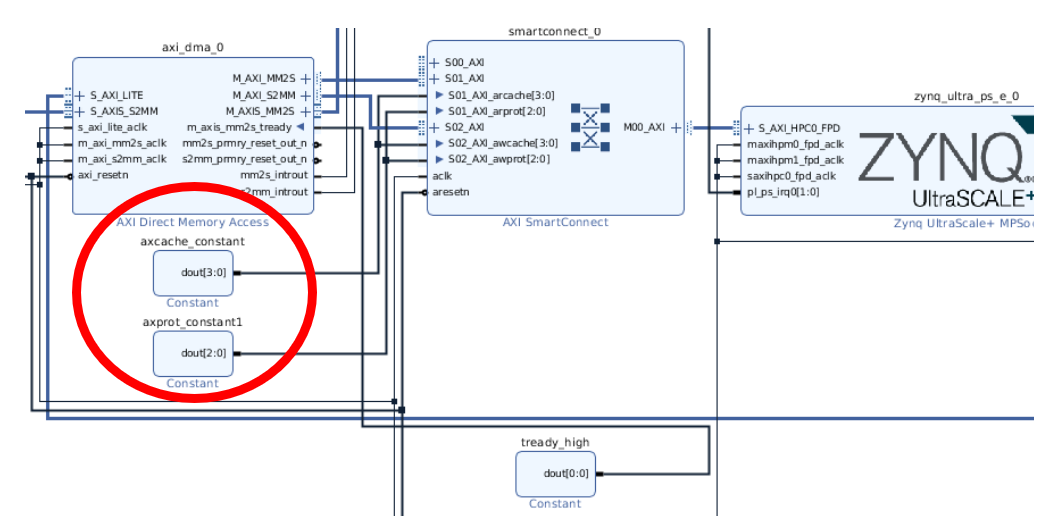
The DMA Proxy driver by default uses coherent memory which is non-cached in a s/w coherent system. A hardware coherent system with cached memory is optional. The example hardware system described below is hardware coherent to allow cached memory without cache maintenance from user space. A coherent capable HP slave interface must be used for hardware coherency.
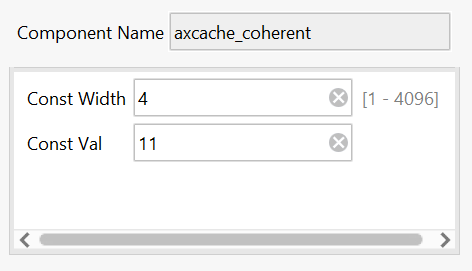
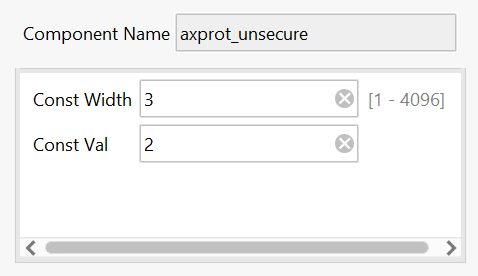
A value of 0x2 is used for the AxProt bus of the AXI stream to allow unsecure transactions as required for Linux. See the Xilinx MPSOC Coherency wiki page for general details at Zynq UltraScale+ MPSoC Cache Coherency. The following illustration shows the general technique for making coherent transactions with the AXI DMA.
Advanced System Techniques
AXI Back Pressure
A default looped back AXI stream, transmit (mm2s) to receive (s2mm), prevents the transmit channel from overrunning the receive channel to cause a loss of data. The tready signal of the AXI stream allows the consumer of an AXI stream to indicate it is not ready to the stream producer so that the flow of data is stopped.
A default looped back AXI stream is easy for prototyping but may not represent a real-life system accurately. A typical A to D converter produces data at a specified data rate assuming there is a consumer of the data at the specified rate otherwise data is lost.
Jitter
Jitter for this prototype is defined to be a lack of predictability of a consumer consuming data at a specified rate. Overall the consumer is consuming the data at the same rate it is being produced, but not consistently. AXI Stream FIFOs can be added in the AXI stream to allow for system jitter. The prototype is running on Linux and by default Linux has some amount of jitter in the system. There are methods to reduce that jitter but that is not the focus of this prototype.
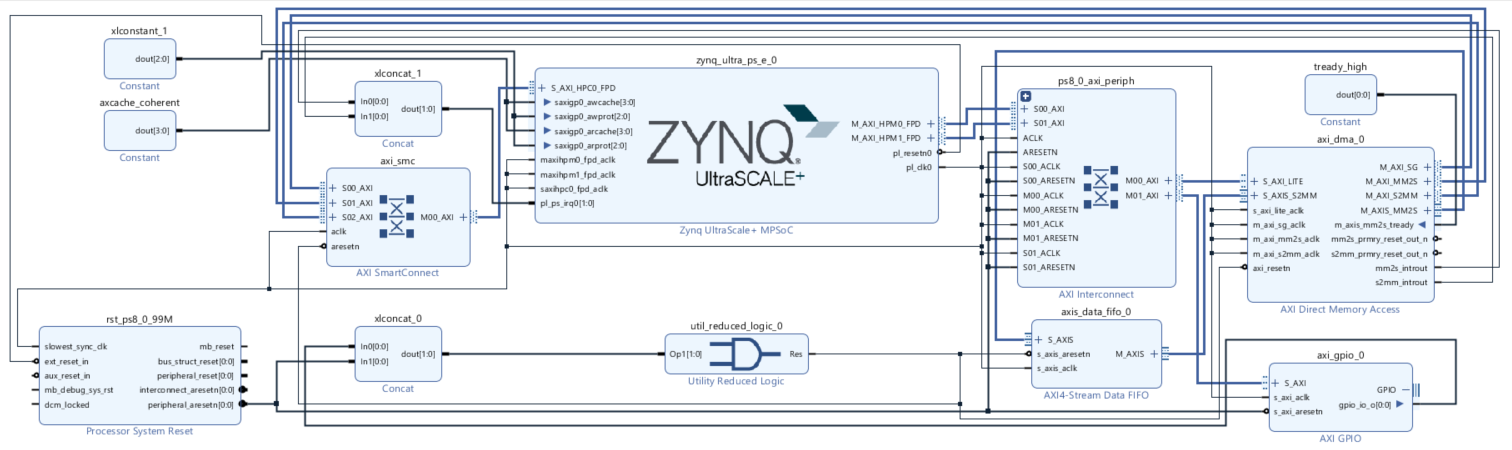
Stream FIFOs
FIFOs can allow system jitter to be absorbed without the loss of data and help to emulate a real-life system such as an A to D converter. The AXI Stream FIFO maximum depth is 32K entries such that it may require multiple FIFOs in the stream depending on the application. The tlast signal must also be turned on to support the DMA channels. When multiple FIFOs are used the receive channel backpressure will cause the FIFOs to fill up from the end closest to the receive channel back towards the transmit channel.
The following system diagram illustrates a Vivado system that does not include back pressure and uses a FIFO between the transmit and receive channels of the DMA.
Software
The DMA Proxy 2.0 moves to a more complex design intended to illustrate how to handle the data of a real-life application.
Functional Changes
The following changes are for both the kernel driver and the application.
Non-Blocking Design
Buffers can now be submitted without blocking for completion. This allows multiple buffers to be submitted and queued along with multiple threads. A blocking wait for the completion of a buffer is also supported to complement the non-blocking submission. The ioctl function of the driver was altered to allow the transfer type to be specified using XFER for the legacy blocking call, START_XFER for starting a transfer using a non-blocking call, and FINISH_XFER to block waiting from the completion of a previously started transfer.
Channel Buffers
Multiple buffers for each channel, transmit and receive, are supported to allow more parallelism and queueing. The number of channel buffers is configurable to enable independent configuration of the transmit and receive channels to help deal with system jitter. A larger number of receive channel buffers can avoid data overruns. The number of channel buffers for the receive and transmit channels can be tuned by altering RX_BUFFER_COUNT and TX_BUFFER_COUNT.
Kernel Details
Proxy Device Tree
The Linux kernel device tree requires a new node for the DMA Proxy driver. The node references the AXI DMA channels in the project. The following snippet illustrates the details of the new node including the use of the dma-coherent property to cause cached memory usage for the optional h/w coherent systems.
| Code Block |
|---|
dma_proxy {
compatible ="xlnx,dma_proxy";
dmas = <&axi_dma_0 0 &axi_dma_0 1>;
dma-names = "dma_proxy_tx", "dma_proxy_rx";
dma-coherent;
} ; |
More device tree examples are contained in the kernel driver source code in dma-proxy.c at https://github.com/Xilinx-Wiki-Projects/software-prototypes .
Kernel Configuration
The AXI DMA kernel driver is required in the kernel and it is controlled by configuration item CONFIG_XILINX_DMA. For ease of resetting the system when DMA errors occur (no backpressure systems) it is easiest to build the Xilinx AXI DMA and Proxy drivers as kernel modules such that they can be inserted and removed from the kernel.
CCI Enablement
The Cache Coherent Interconnect (CCI) must be enabled prior to Linux booting for h/w coherent systems. This is done by default in 2020.1 such there is no change required while it may not be the case in prior releases. The boot.bin file is built using the bootgen method of enabling system coherency as described in the paragraph “Register Write At Early Boot” on the Xilinx MPSOC Coherency wiki page at Zynq UltraScale+ MPSoC Cache Coherency.
Dma-proxy-test Application Details
The application allows the user to control the number of DMA transfers to perform, the number of KBytes in each transfer, and if the data is to be verified.
The application starts a thread to handle the transmit processing in parallel with the receive processing. The transmit thread is created with a lower priority to help prevent it from overrunning the receive processing. The receive processing is also boosted to be high priority for the same reason. The pthread library is required to support threads.
Processing was added to the application to allow it to be aborted using control C (or kill) and then gracefully exit. The transmit and receive processing must be synchronized prior to exist such that DMA transfers are not pending.
Results
The following run of the test shows an example performance with a 300 MHz PL and 128 bit AXI interfaces for the DMA.
root@xilinx-zcu102-2020_1:~# dma-proxy-test 100000 128 1
DMA proxy test
Verify = 1
Normal Buffer Performance: Time: 247189 microseconds, Test size: 128000 KB, Throughput: 530 MB / sec
DMA Buffer Performance : Time: 247364 microseconds, Test size: 128000 KB, Throughput: 529 MB / sec
Time: 16180500 microseconds
Transfer size: 12800000 KB
Throughput: 810 MB / sec
DMA proxy test complete
Source Code
The source code is still very similar to the original simple design with a kernel driver (dma-proxy.c) and a test application for user space (dma-proxy-test.c) with a shared header file (dma-proxy.h). The source code is located at https://github.com/Xilinx-Wiki-Projects/software-prototypes in the linux-user-space-dma directory. The similar DMA proxy source code is also applicable for Versal design.
System Observations
The number of interrupts for the transmit and receive channels is not always identical. This is not an issue as the lower layer driver can support interrupt coalescing.
Quick Start
The following steps outline the system build process assuming the details are understood.
Hardware
Build a default Vivado MPSOC system for any supported board.
Add the AXI DMA with Scatter Gather connected to the slave HPx port (HPCx for h/w coherent systems) of MPSOC with interrupts
Tie the AXI signals (AxCache and AxProt) on the AXI Streams (not SG) of the DMA for h/w coherent systems
Software
Build the proxy driver and kernel, ensuring the AXI DMA driver is in the kernel
Add the proxy node to the device tree
Add the property “dma-coherent” in the proxy node of the device tree when using a h/w coherent system
For prior tool releases, build the boot.bin with register initialization with bootgen to turn on system coherence for h/w coherent systems
Build the application with pthread support
Known Issues
The Width of Buffer Length Register of the DMA defaults to 14 bits for only smaller transfers. Larger transfers, such as the example command line for 128K, can cause an error with a “prep error” printed and possibly a kernel dump of the driver. Smaller transfer sizes with testing should avoid the issue.